Every LLM session gets
more expensive as it runs.
That's arithmetic. Not a bug.
Turn N costs proportional to N. Total: O(N²). OpenAI didn't fix it. Anthropic didn't fix it. Google didn't fix it. They built better models. Nobody eliminated the replay.
Burnless eliminates it. Not by asking the LLM to be careful. Not by summarizing before each call — that is still O(N²) with a smaller constant. By separating Cognitive Execution (Workers) from State Management (Capsules/Maestro) — the same move TCP/IP made when it separated applications from the network. Workers receive the current task only. The Brain prefix never changes so it stays cache-hot. The quadratic term is not reduced. It is structurally impossible.
Proof: 16× reduction in real API consumption on the heaviest development day on record — 1% of weekly quota used, versus 97% the week before without the protocol. That number does not exist if the problem was already solved.
We compress pages of conversation history into a single 80-character line. Your AI keeps the memory. You stop paying for the excess.
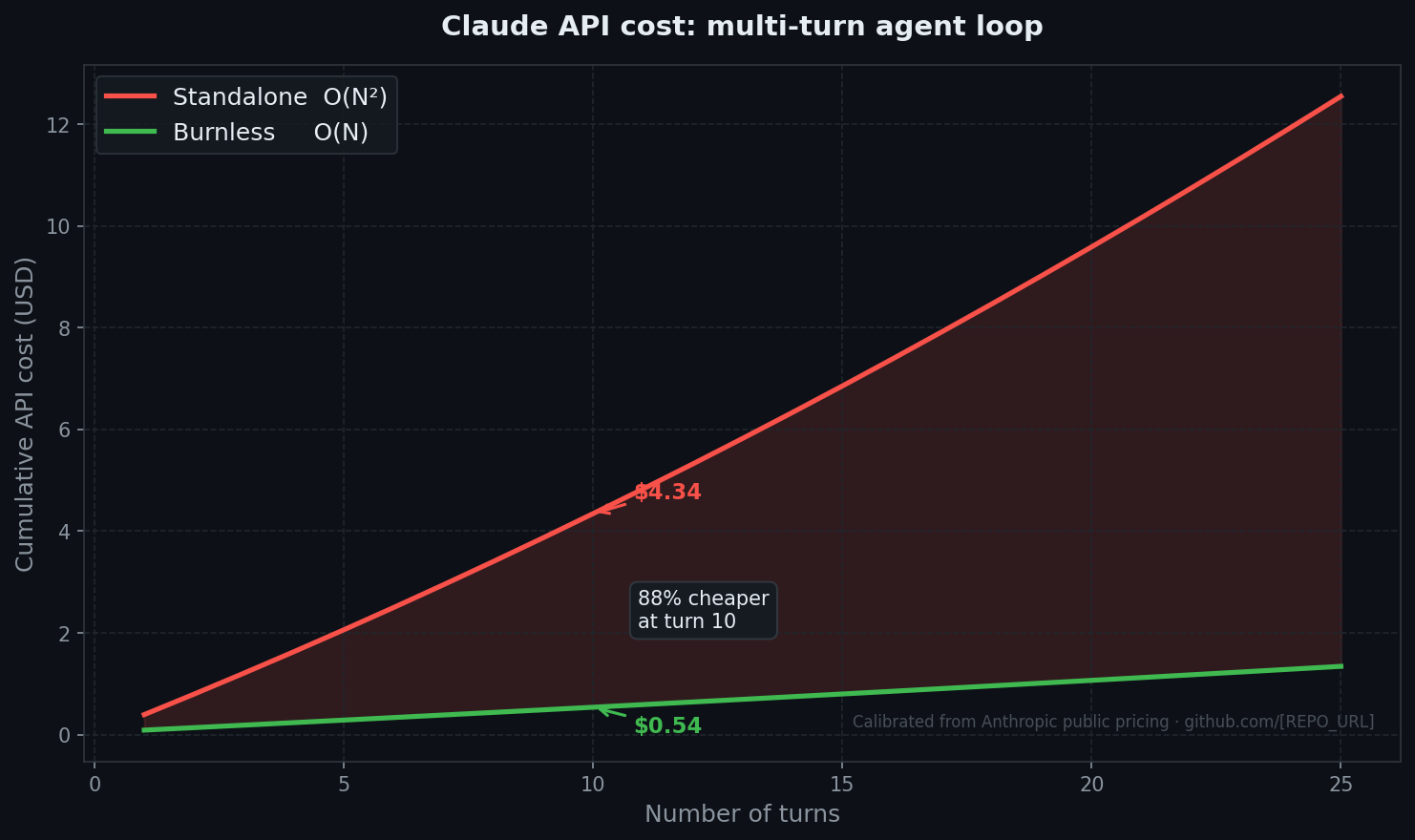
Calibrated from real Anthropic API runs. Reproduce: python bench/v2.py --simulate
Turns Standalone Burnless Savings 2 $0.80 $0.14 82.7% 5 $2.06 $0.29 86.1% 10 $4.34 $0.54 87.6% 20 $9.59 $1.07 88.9% 50 $30.72 $2.83 90.8%
Without Burnless $2.45 With Burnless $0.28 Real saving 88%
pip install burnlessBeyond cost. The protocol layer.
A token is not an abstraction. It is compute. Compute is electricity. Electricity is water and infrastructure. O(N²) at the scale LLM inference is heading — 1–5% of global electricity within a decade — is not a pricing quirk. It is a trajectory.
Burnless is the transparent, provider-agnostic layer that sits between any user and any LLM, converting O(N²) context growth into O(N) by design. Not a feature. Not an SDK wrapper. A candidate protocol — like TCP/IP was to packets. The model receives a capsule. The user sends a message. The orchestration layer speaks compact state.
60–90 TWh/year
Estimated energy saved at 1% of global LLM inference. Denmark's entire electricity consumption is 35 TWh/year. This is not a rounding error.
Structurally unblockable by design
A semantic capsule is a dense summary of session state sent as ordinary text. The protocol needs no provider-specific feature to carry compact state.
Inevitable. Open.
This layer will exist. The question is who defines it and in whose interest. Burnless answers: MIT, documented, first.
Why the curve is quadratic.
Every turn in a standalone agent loop replays the full conversation as input. Cost on turn N is proportional to N, so total cost across N turns is Θ(N²). That is arithmetic from the pricing page, not a property of any SDK.
1. Capsules, not transcripts
Brain history holds ~80-char summaries of each turn, not the raw exchange. Full output stays on disk, read on demand.
2. Shared prefix cache
System prompt is byte-identical every turn with cache_control. Read price ($0.15/MTok) instead of write price ($15/MTok). 100× spread.
3. Tiers are roles, not models
Any model as Brain. Any model as Worker. GPT-4o, Opus, Sonnet, Codex, Ollama — one-line config change.
4. Living glossary
Core terms, project terms and session deltas form a compact language between human intent, Maestro and Workers.
5. Privacy by architecture
Run encoder/decoder locally → cloud sees only capsules, not raw text. Run Maestro locally → cloud workers see disconnected task fragments with zero conversation context. Four levels, one config line.
We don't ask you to trust the table. Reproduce it: python bench/run.py --turns 8 with your own API key.
How it looks.
A chat-first CLI. Slash commands users already understand. Compact state under .burnless/. No hosted backend.
# in any project $ pip install burnless $ burnless setup $ burnless # Burnless Chat — /commands, /maestro, /model, /workers, /native $ burnless delegate "fix the failing tests" → d001 routed to silver/codex (matched: test) $ burnless delegate "summarize the logs" → d002 routed to bronze/haiku (matched: summarize) $ burnless run d002 heartbeat: reading · idle 7s (ephemeral) OK:d002 — typed report + capsule saved
Gold/silver/bronze are quality/cost bands, not vendors. The default setup can mix Claude, Codex and Ollama; users can replace any tier in .burnless/config.yaml.
Cache compaction is realtime ROI math: Burnless freezes immutable blocks and only creates a new super-capsule when future cache-read savings beat the write+compaction cost.
Editions.
The protocol is MIT and stays free. Pay for the things organizations need to trust it at scale: governance, compliance, and team infrastructure.
Burnless
Free · MIT
- Open protocol, MIT licensed
- Full CLI, runs locally
- Brain + Worker + capsule history
- Shared prefix cache, realtime capsule compaction
- Typed execution/thought reports with evidence audit
- Ephemeral heartbeat progress without scroll-history noise
- Local burnkey semantics planned in the protocol
- Provider-agnostic — any LLM as Brain or Worker
- Reproducible benchmark
Burnless Cloud/Enterprise
Soon · waitlist
- Shared cache across machines and teammates
- KMS/HSM key custody and retention policy
- Audit logs, legal hold and destruction reports
- SSO + team permissions
- Dashboards, SIEM/webhooks and priority support
Don't trust the table. python bench/run.py --turns 8 with your own API key.
Burnless Cloud — waitlist.
Hosted features for teams: shared cache, dashboards, KMS/HSM key custody, audit logs, SSO and retention policy. The protocol is free and open source — Cloud/Enterprise is for organizations that need governance.